Workflow Documentation#
This section will give you some general guidelines on documenting your analysis data and code.
Data diagrams#
Data diagram tools like Mermaid and PlantUML
are useful to document data processing flows and some can be embedded into Markdown files such as a README.md file.
By using diagram tools:
modifications to flowcharts do not have to be re-uploaded with new images every time.
Markdown syntax is intuitive therefore documentation process is more efficient.
Tip
You may reuse the following source code examples to document your GitHub project repository.
Add the source code in your README.md file and make changes to it to document your data flow.
Examples of Data Filtering and Data Integration diagrams created by mermaid.
Documenting data selection (rendered diagram):
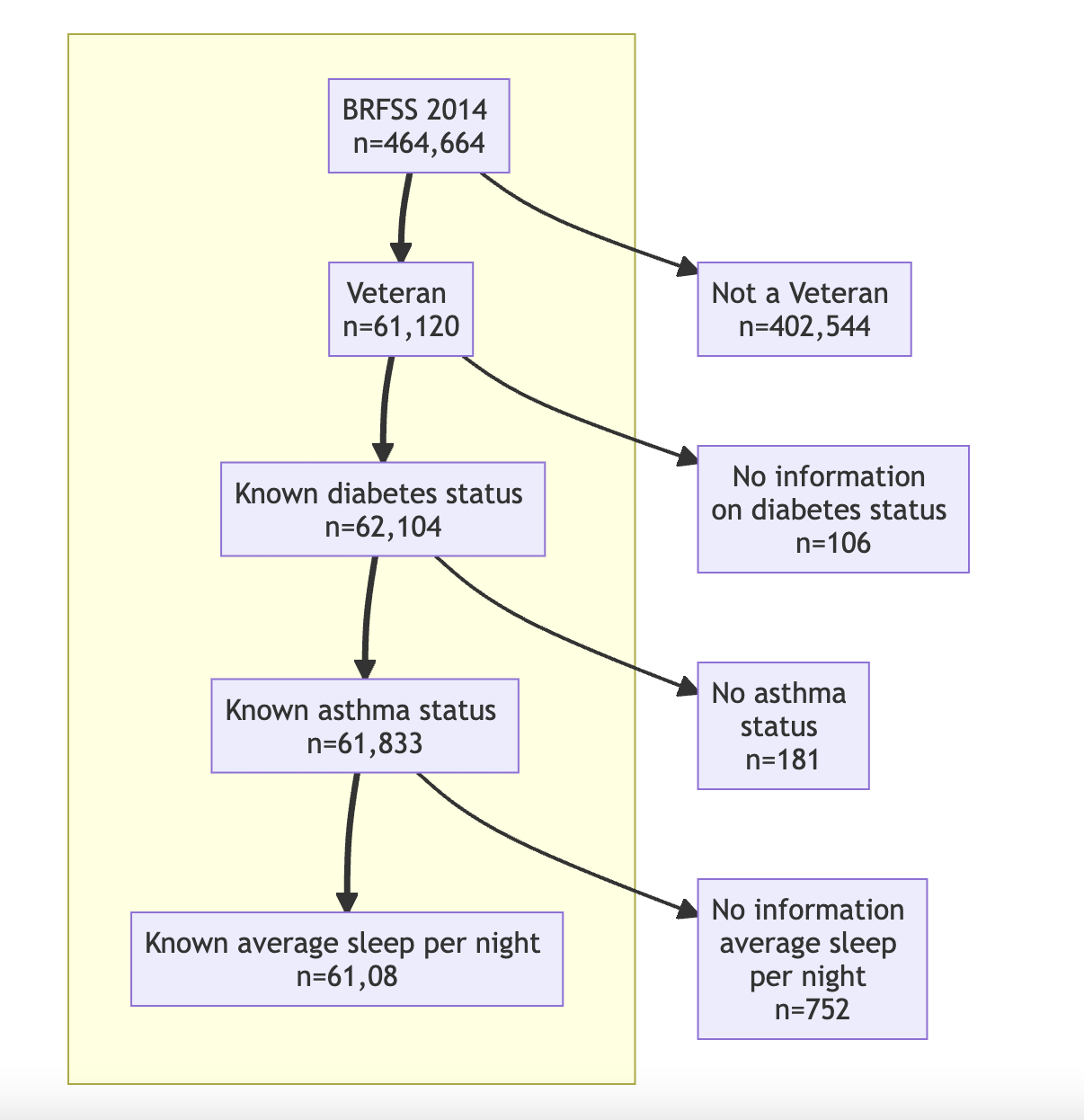
Fig. 9 Example data process flow diagram#
Source code of the diagram for the Markdown file:
```mermaid
flowchart TB
subgraph ID100[ ]
ID1[BRFSS 2014 \n n=464,664]==>ID2[Veteran \n n=61,120]
ID2==>ID3[Known diabetes status \n n=62,104]
ID3==>ID4[Known asthma status \n n=61,833]
ID4==>ID5[Known average sleep per night \n n=61,08]
end
ID1-->ID10[Not a Veteran \n n=402,544]
ID2-->ID11[No information \n on diabetes status \n n=106]
ID3-->ID12[No asthma \nstatus \n n=181]
ID4-->ID13[No information \n average sleep \n per night \n n=752]
```
Documenting data sources (rendered diagram):
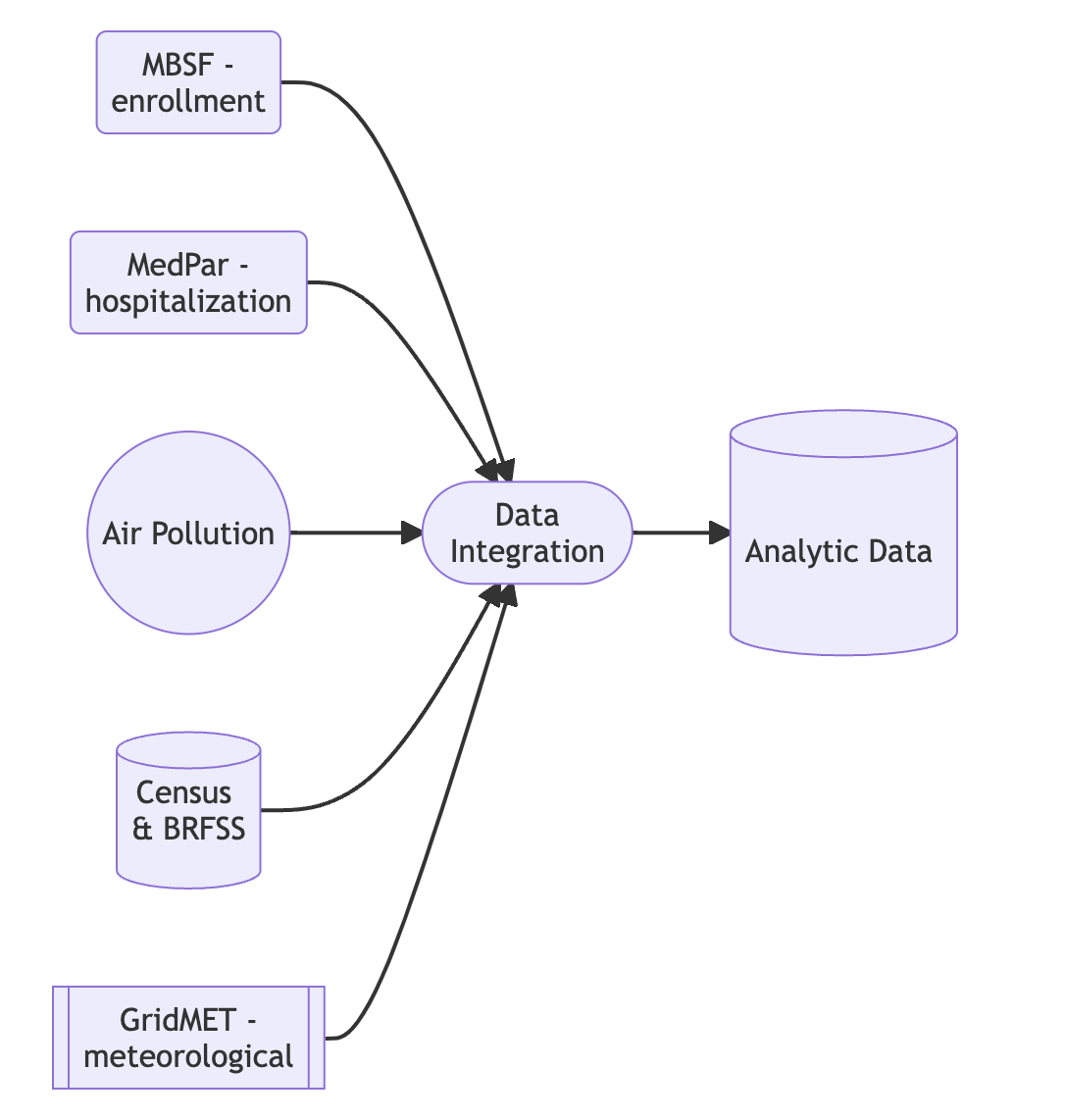
Fig. 10 Example data integration diagram#
Source code of the diagram for the Markdown file:
```mermaid
flowchart LR
%% creating nodes
id1([Data\n Integration])
%% linking nodes
id2(MBSF -\n enrollment)-->id1
id3(MedPar -\n hospitalization)-->id1
id4((Air Pollution))-->id1
id5[(Census \n& BRFSS)]-->id1
id6[[GridMET -\n meteorological]]-->id1
%% integration to warehouse
id1-->id7[(\n\n Analytic Data \n\n)]
```
See more examples on Github.
Data dictionary#
A data dictionary is important to communicate to other data users about the content of your data. When you have many variables in your dataset, you can create a dictionary that shows what each variable represents, what data type it is stored as (string, int, etc.), and any other pertinent information, such as what the missing values are encoded as. If you are including a measure as one of your variables, you should include the units of the measure (e.g. grams, degrees Celsius, etc.) in your data dictionary. Below is an example of what a few rows of a data dictionary may look like.
Variable |
Description |
|---|---|
UserID |
An 8 digit integer containing the user ID for each individual |
DOB |
The user’s date of birth, encoded as MMDDYYYY. Missing values are encoded as “99999999” |
WGT |
An integer containing the user’s weight in kilograms. Missing values are encoded as “-1” |
CVD_HSP_PST_YR |
A binary variable which states whether the individual has been hospitalized for cardiovascular disease in the past year. |
Tip
View an example of a data dictionary here: ShuxinD/ADRDdata
Code documentation#
A README.md file is a standard documentation file where you should put information about the content of your repository.
Consider adding some of these standard sentences in your README.md file (change them as needed):
Software requirements
We use the R version: 4.x.y
We use Python 3.x.y
You can execute this code in RStudio
You can execute this code in the command line as follows:
RScript analysis.R
Data Availability
All data are publicly available. / Some data cannot be shared publicly. / No data can be shared publicly.
We use data from the following data sources:
List data sources.
Medicare/Medicaid. It cannot be shared, but you may find synthetic data from CMS here.