MedPAR Outcome Datasets Overview#
The MedPAR Outcome Datasets in the LEGO data catalog provide researchers with access to processed inpatient admission records for Medicare beneficiaries, where each beneficiary admission is tagged and filtered with a health outcome based on predefined ICD-9 and ICD-10 diagnosis codes. These curated datasets reflect hospitalizations associated with specific medical conditions.
This walkthrough guides users through navigating the data catalog, identifying outcome-specific datasets, determining whether an existing dataset meets study requirements, and leveraging ICD Codes YAML configuration files to ensure consistency and reproducibility in outcome definitions.
Step 1 : Assessing the MedPAR Outcomes Content#
To begin exploring the MedPAR Outcome Datasets, access the data catalog and navigate to the Medpar Outcomes section in Medicare or Legacy Medicare section. It provides a centralized view of curated outcome-specific inpatient datasets, along with documentation, metadata, and data paths to support outcome selection and reuse.
Step 2 : Exploring the Available Outcomes dataset#
Within the Content tab of the catalog, each folder represents a project submission from a specific researcher, named using the format <pi_name>_<researcher_name>_<project_number> (e.g., antonella_ernani_00, michelle_yongsoo_01).
Expanding the folder displays a list of .parquet files, each representing outcome-tagged inpatient admissions for Medicare beneficiaries. These files follow a standard naming convention: <outcome>_<yyyy>.parquet, where <outcome> refers to the diagnosis (e.g., diabetes, cvd, melanoma) and <yyyy> denotes the calendar year.
Clicking on a .parquet file displays the data dictionary, and provide additional context such as a link to the github icd code yaml file.
The Subdatasets view also includes a searchable list of all available outcome files. You can apply a filter based on diagnosis to easily locate specific outcomes of interest.
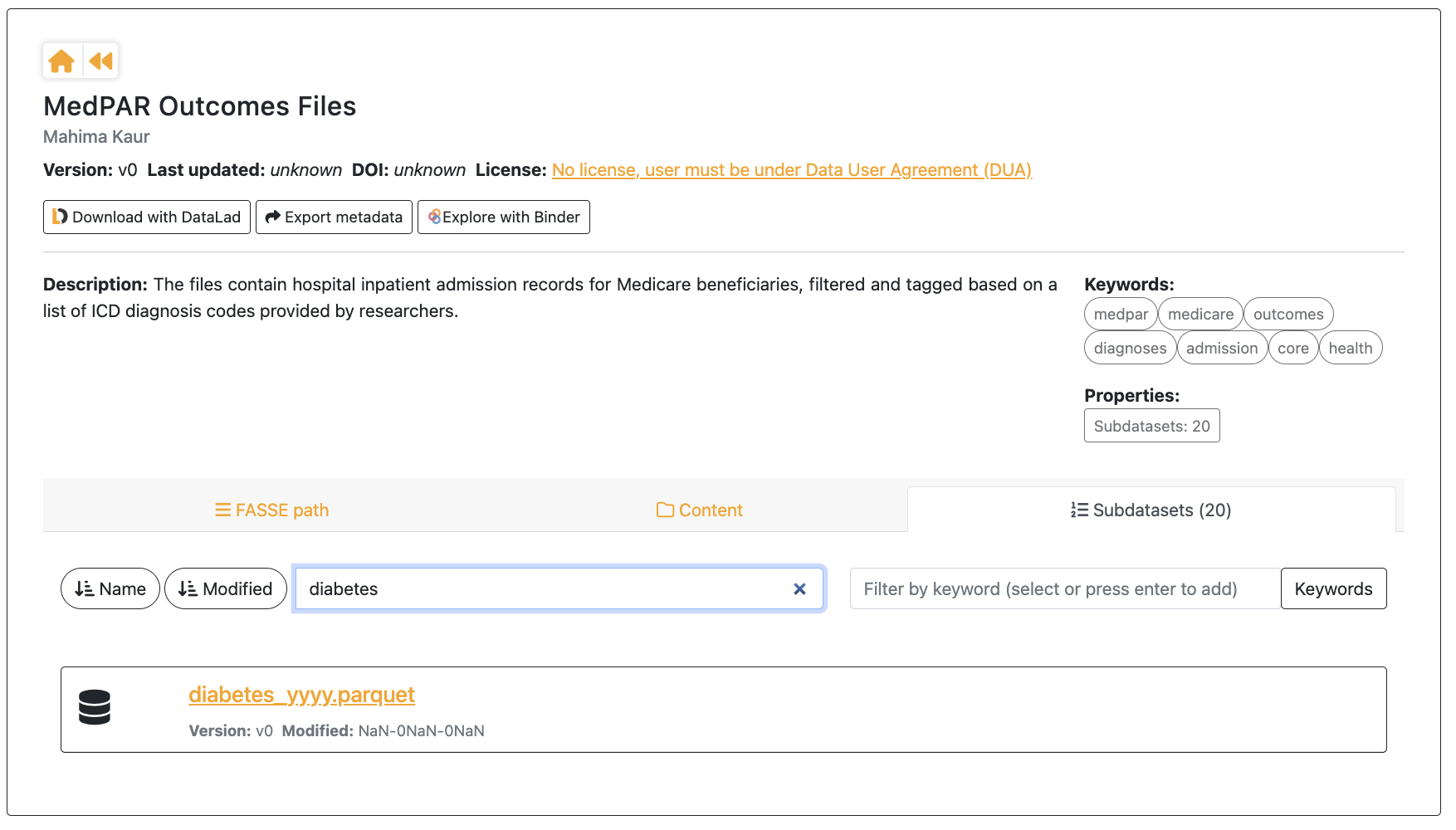
Step 3 : Reusing Previously Created Outcome Datasets#
Researchers are encouraged to reuse existing outcome-specific .parquet files when the dataset aligns with the goals and criteria of their study. Reusing curated datasets helps reduce duplication of effort and promotes consistency in cohort definitions across projects.
Before reusing a dataset, carefully review the associated ICD codes and outcome criteria to ensure it matches your research definition. In some cases, multiple users may have created datasets for the same condition. It’s important to assess which version best fits your study requirements.
Each outcome dataset is generated using an ICD-based YAML configuration file, which defines :
The list of ICD-9 and ICD-10 codes used for identifying the outcome
The outcome criteria (e.g., whether to evaluate all diagnosis codes or only the primary/few initial ones).
The YAML files are available on the GitHub repository : NSAPH-Data-Processing/medpar_outcomes
If the desired outcome dataset is not available, the researcher can complete the project initiation form to request a new dataset, specifying the ICD-9 and ICD-10 codes and outcome criteria to be used.