LEGO Data Model#
Overview#
The LEGO Data Model is a structured framework designed to standardize data storage, structure, and management across various projects. By adopting a modular approach—similar to LEGO building blocks—we ensure consistency, reproducibility, and scalability in data organization.
Access the LEGO Catalog at 🔗 https://lego-catalog.netlify.app/

Why the LEGO Data Model?#
The LEGO Data Model is inspired by the modularity and standardization of LEGO blocks. Its key principles include:
Modular Structure: Data is organized into well-defined, reusable components.
Standardized Formats: Ensures interoperability between datasets.
Hierarchical Organization: Data is structured by domains, subdomains, and time resolutions.
Predefined Schema: Every dataset follows a standard schema with linking elements like county IDs.
Data Standards in the LEGO Data Model#
File Formats#
To optimize storage and processing, the LEGO Data Model supports:
Parquet: Columnar storage format for tabular data.
Shapefile (SHP): Used for spatial data.
Folder Structure & Naming Conventions#
All datasets in our lab follow a structured hierarchy to ensure logical arrangement and easy access.
Folder Hierarchy Example#
<main lab folder>/lego
├── <domain>
│ ├── <subdomain>__<data_source>
│ │ ├── <geo_resolution>__<time_resolution>
│ │ │ ├── <filename>_yyyy.parquet
Key Folder Components#
Domain: Broad research category (e.g., health, environment, social).
Subdomain: Specific dataset type (e.g., hospitalization, demographics, air pollution).
Data Source: The origin of the dataset (e.g., Medicare, Medicaid).
Geographic Resolution: The spatial granularity (e.g., county, state, ZCTA).
Time Resolution: The temporal frequency (e.g., annual, monthly, daily).
File Naming Convention: Maintains consistency for dataset identification.
Notes#
Files are stored yearly.
All files that share a common datapath/filename should have identical variables/columns.
Navigating the LEGO Data Model#
The LEGO Data Model includes five domains, accessible via :
CANNON
/n/dominici_lab/lab/lego(excluding health)ReD
lab_share/data/lego(lab_sharerefers to the lab share directory, which remains confidential for security reasons)
Domains#
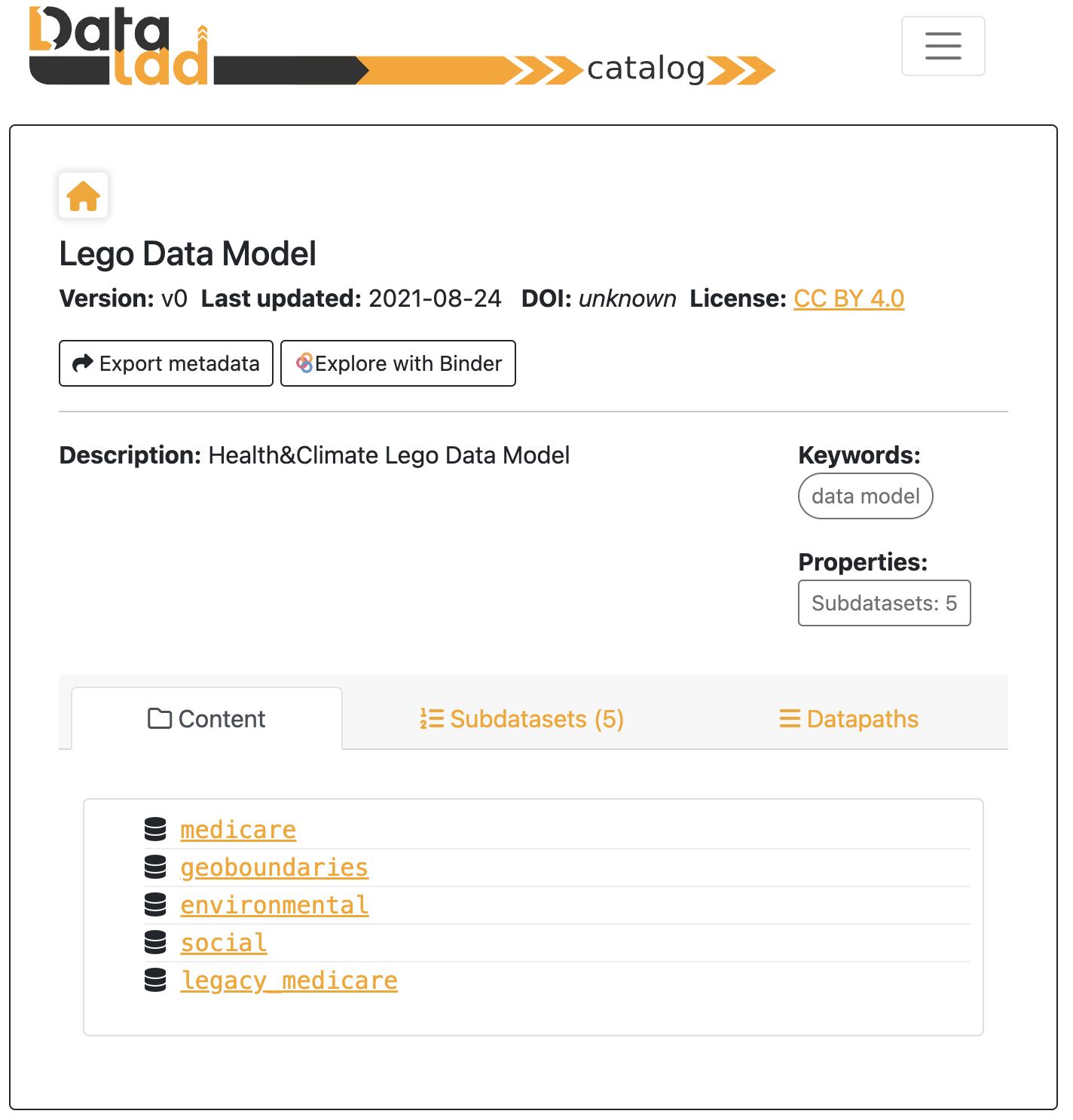
From the home of the LEGO Catalog, both the Content and Subdatasets tabs list the LEGO domains:
medicare– Core datasets related to Medicare beneficiaries, encompassing health outcomes such as mortality, hospital admissions, and conditions including cardiovascular diseases, respiratory diseases, cancer, asthma, Alzheimer’s disease and related dementias, among others. The end-to-end preprocessing is fully reproducible and extensible.legacy_medicare– Datasets related to Medicare derived from preprocessed denominator and admissions data. The “legacy” denomination is utilized as the processing steps from the raw source are not fully reproducible and therefore the product cannot be continued or extended.environmental– Datasets capturing environmental exposures, including climate-related factors (temperature, cyclones, humidity, heat alerts, and heat waves) and pollution data.geoboundaries– Geographical datasets containing shapefiles, crosswalks, and unique geospatial identifiers sourced from the U.S. Census Bureau. These datasets are essential for linking health and environmental data to geographic areas. Within the LEGO data model they represent the “geographical backbone” of the data.social– Datasets providing demographic and socioeconomic insights such as population distribution by age groups, ethnic composition, housing statistics, and other key social variables.
Dataset Details#
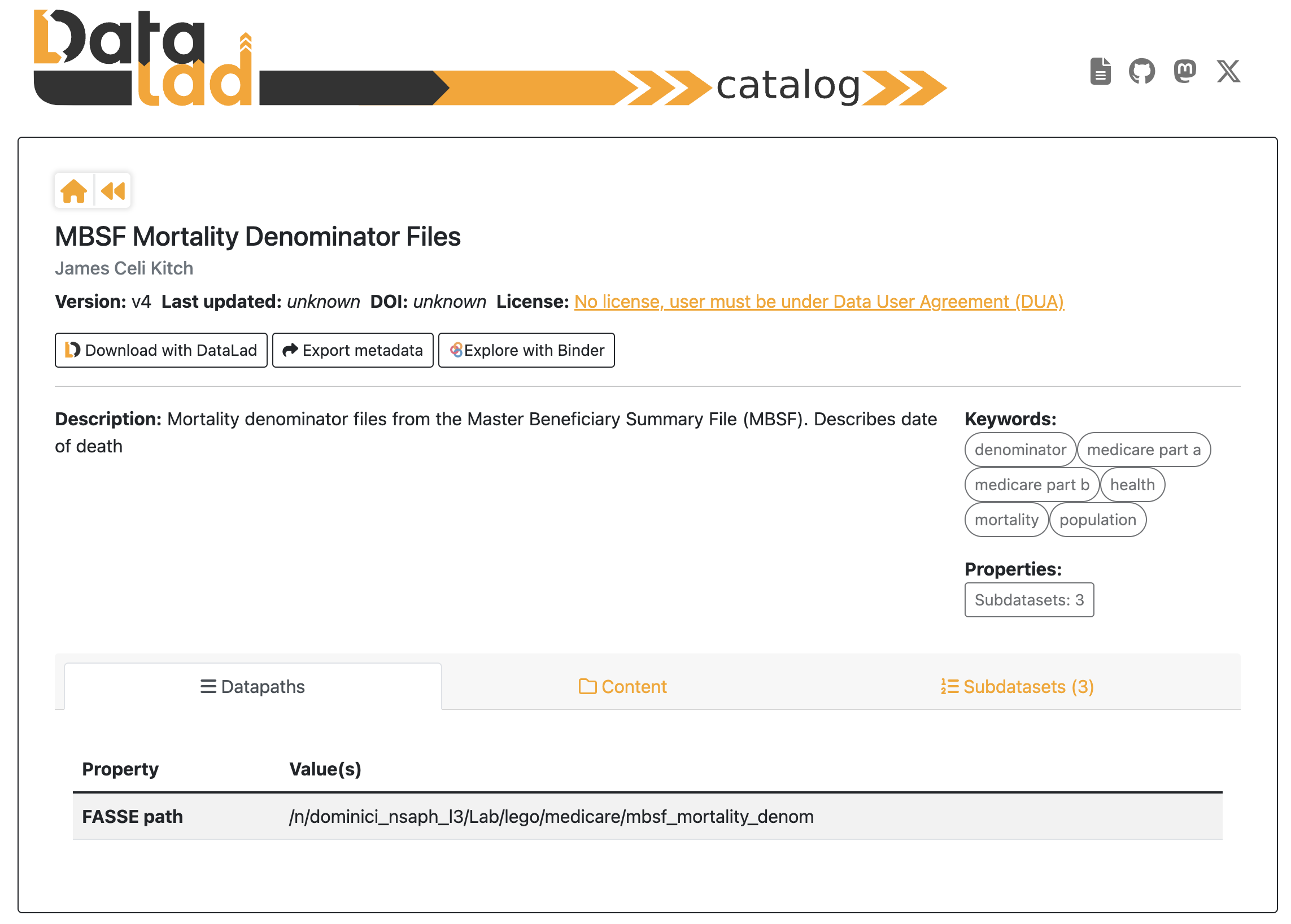
Each dataset page provides:
Description – Overview of the dataset including Keywords and Properties..
Datapaths – Folder location for dataset access.
Content or Subdatasets – List of files within the dataset.
Each file page includes:
Description – Overview of the file contents.
Data Dictionary – Comprehensive list of variables and their descriptions.
Example: Navigating the Medicare Core Datasets#
Access the Dataset Overview : Navigate to the Home Contents tab and select
medicare. View the description, metadata, file path, and keywords.
View the Content or Subdatasets : Click the Content or Subdatasets tabs to explore related files (e.g., mortality, admissions, outcomes).
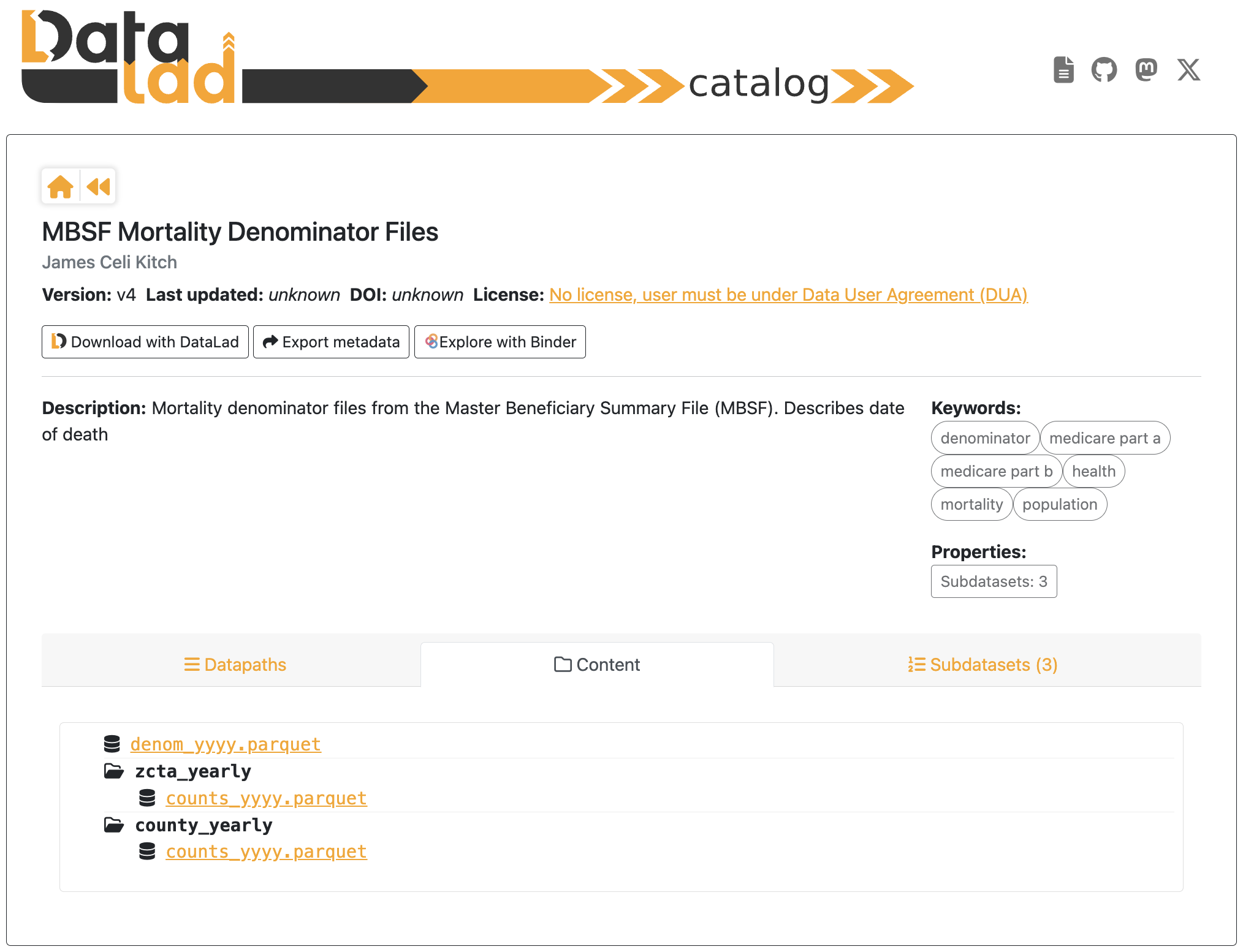
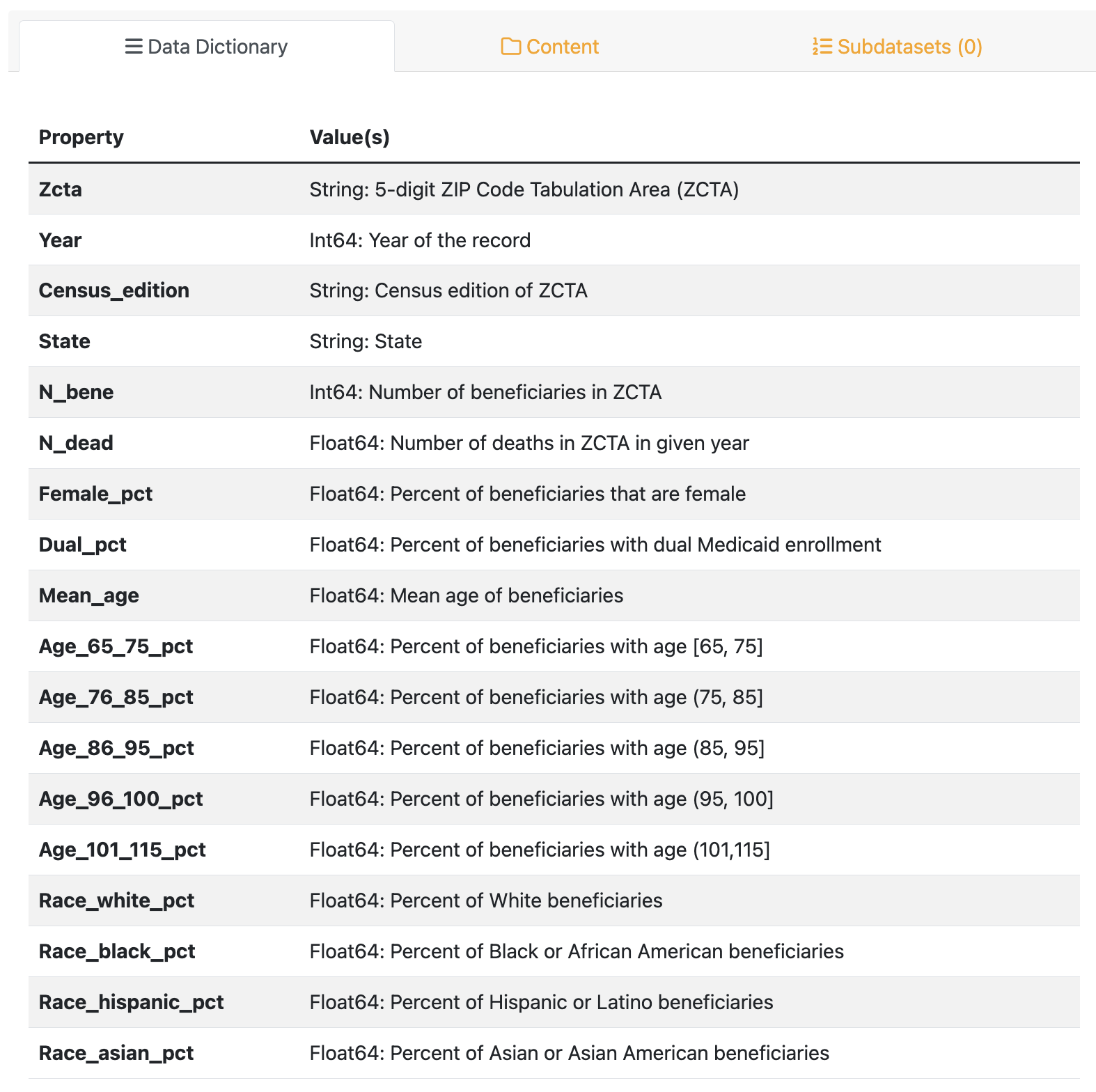
Explore Specific Files : Click on a file to view its data dictionary (e.g.,
zcta_yearly → counts_yyyy.parquet).
Leveraging the LEGO Data Model for Data Requests#
The LEGO Data Model ensures consistency, collaboration, and reproducibility. Researchers can search for datapaths, data dictionaries, and associated data pipelines on github, to collaborate seamlessly through a shared centralized dataset structures.